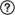View
View the list of k-mers composing the motif
P-value: The value presented is the mHG score corrected for multiple testing, which is a tight bound for the P-value.
N: the total number of sequences analysed.
B: the total number of sequences containing the motif.
n: the index, in which the division of the input list into target and background by the mHG statistics, gives the optimal enrichment of the motif at the top of the list.
b: the number of sequences containing the motif among the top n sequences.
Enrichment: measures to what extent the motif is found at the top of the list comparing to total list. Defines as: (b/n) / (B/N).
| K-mer |
P-value ≤ |
N |
B |
n |
b |
Enrichment |
| Uugua |
6.12E-09 |
10000 |
328 |
419 |
43 |
3.13 |
| uguaA |
1.36E-07 |
10000 |
357 |
873 |
68 |
2.18 |
| CUgua |
3.09E-07 |
10000 |
244 |
598 |
41 |
2.81 |
| cugua |
3.41E-07 |
10000 |
269 |
372 |
33 |
3.30 |
| uaugu |
5.23E-07 |
10000 |
438 |
955 |
82 |
1.96 |
| uuugu |
5.60E-07 |
10000 |
398 |
1021 |
80 |
1.97 |